Rancher Kubernetes Engine - Backups and Disaster Recovery
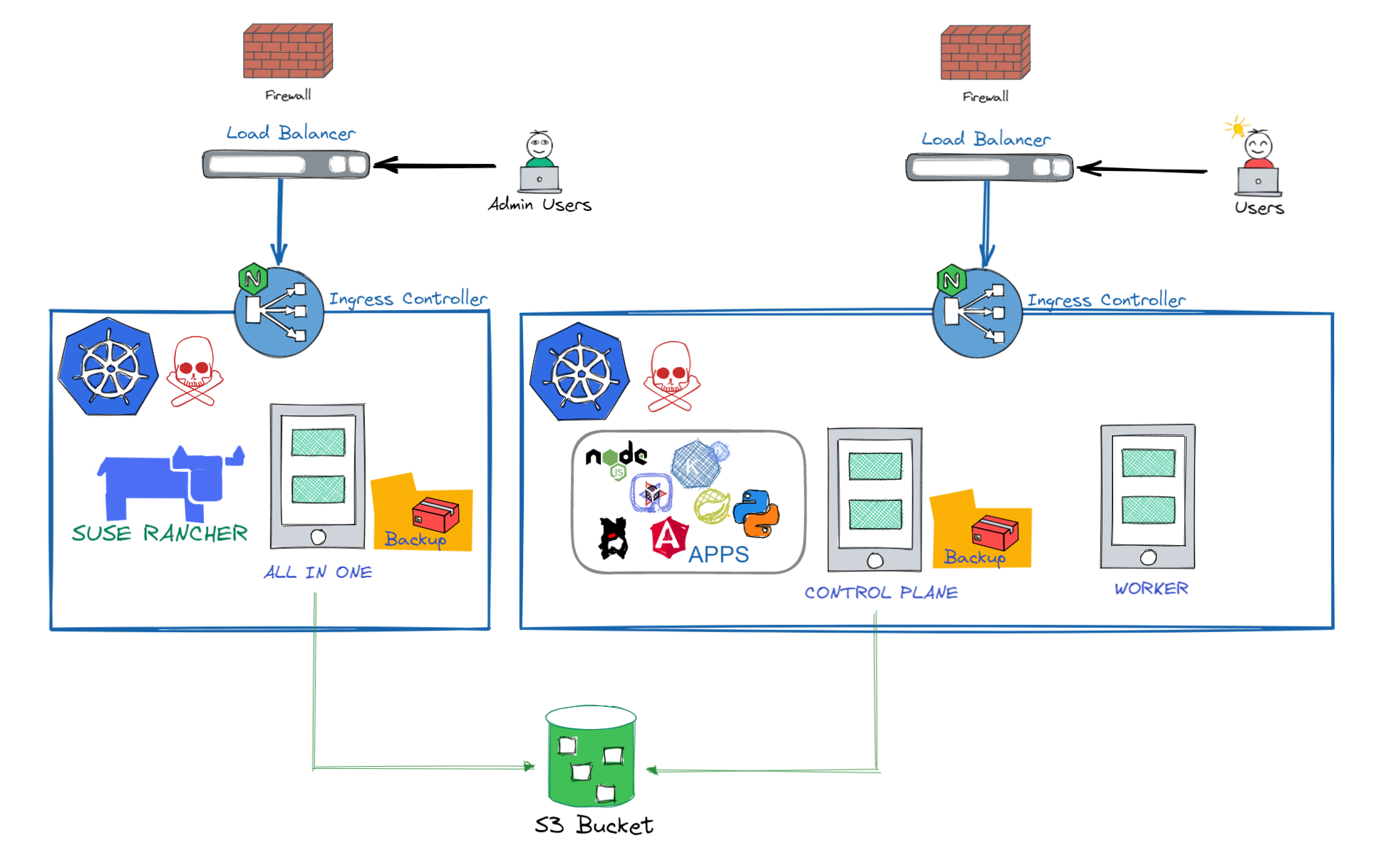
RKE Snapshots
Los clústeres de RKE se pueden configurar para tomar Snapshot (Copia de Seguridad) de etcd automáticamente. En un escenario de desastre, puede restaurar estos Snapshot, que se almacenan en otros nodos del clúster. Los Snapshot siempre se guardan localmente en los servidores con rol ETCD en la ubicación: /opt/rke/etcd-snapshots.
RKE puede cargar sus Snapshot en un backend compatible con S3.
Puede crear Snapshot únicos para hacer una copia de seguridad de su clúster y también puede configurar Snapshot recurrentes.
Puede usar el mismo binario de RKE para restaurar su clúster a partir de una copia de seguridad.
Cómo funcionan los Snapshot
Para cada nodo etcd en el clúster, se verifica el estado del clúster etcd. Si el nodo informa que el clúster etcd está en buen estado, se crea un Snapshot a partir de él y, opcionalmente, se carga en S3.
El Snapshot se almacena en /opt/rke/etcd-snapshots. En S3, el Snapshot siempre será del último nodo que la cargue, ya que todos los nodos etcd la cargan y el último permanecerá.
En el caso de que existan varios nodos etcd, cualquier Snapshot creado se crea después de que se haya verificado el estado del clúster, por lo que puede considerarse un Snapshot válido de los datos en el clúster etcd.
Cada Snapshot incluirá el archivo de estado del clúster además del archivo del Snapshot de etcd.
Para guardar un Snapshot una sola vez de etcd de cada nodo de etcd del clúster, ejecute el comando rke etcd snapshot-save de la siguiente manera:
$ rke etcd snapshot-save --config cluster.yml --name snapshot-name
Al ejecutar el comando, se crea un contenedor adicional para tomar el Snapshot. Cuando se completa el Snapshot, el contenedor se elimina automáticamente. El Snapshot se guarda en /opt/rke/etcd-snapshots.
Para guardar un Snapshot única en S3, ejecute el comando como el siguiente ejemplo: $ rke etcd snapshot-save --config cluster.yml --name snapshot-name --s3 --access-key S3_ACCESS_KEY --secret-key S3_SECRET_KEY --bucket-name s3-bucket-name --folder s3-folder-name --s3-endpoint s3.amazonaws.com
El resultado será que el Snapshot se guarda en /opt/rke/etcd-snapshots y también se carga en el backend de S3.
Laboratorio: Backups y Disaster Recovery de RKE
Descripción
La presente guía ayuda a realizar un respaldo o Snapshot de un cluster RKE por medio de la data almacenada en ETCD y el archivo de estado del Cluster.
Objetivos
- Realizar un respaldo o Snapshot de un cluster RKE utilizado para aplicaciones de usuarios
- Realizar un respaldo o Snapshot de un cluster RKE donde se encuentra instalado Rancher Server
- Llevar a cabo la restauración de un cluster RKE de aplicaciones de usuarios
- Llevar a cabo la restauración de Rancher Server mediante un Snapshot de RKE
Parte 1: Backups y Disaster Recovery de RKE Cluster Users
-
Ingresar al ambiente de laboratorio en el servidor student-#-aio al cluster de usuarios de Kubernetes, exportar la variable de ambiente KUBECONFIG
export KUBECONFIG=~/rke-cluster-users/kube_config_cluster.yml -
Crear un nuevo Namespace para llevar a cabo una nueva publicación de una aplicación para simular su restauración y recuperación ante un desastre:
kubectl create ns example-backup-recovery -
Ejecutar el siguiente comendo para realizar el Deployment nuevo de una aplicación, en este ejemplo se esta llevando a cabo un despliegue de un servicio de NGINX.
kubectl create deployment deployment-backup-recovery --image nginx -n example-backup-recovery -
Verificar que el deployment se realizó corerctamente con los siguientes comandos:
kubectl -n example-backup-recovery rollout status deploy/deployment-backup-recoverykubectl -n example-backup-recovery get pods -
Ingrese al directorio ~/rke-cluster-users, debe asegurarse de encontrase ubicado en el directorio anterior, de lo contrario la ejecución de la toma del Snapshot fallará:
cd ~/rke-cluster-users -
Ahora que se se cuenta con una Deployment de una aplicación de ejemplo, se procede a tomar el Snapshot o Respaldo:
Cuando la toma del Snapshot termine, deberá visualizar un mensaje similar al siguiente:rke etcd snapshot-save --name snapshot-users.db --config ~/rke-cluster-users/cluster.ymlINFO[0005] Waiting for [etcd-snapshot-once] container to exit on host [student-0-master] INFO[0005] Removing container [etcd-snapshot-once] on host [student-0-master], try #1 INFO[0005] Finished saving/uploading snapshot [snapshot-users.db] on all etcd hosts -
Ingrese al servidor student-X-master, el cual tiene el rol de ETCD en el ambiente de laboratorio:
ssh student@student-X-master -i ~/student-X-private_key.pem -
Verifique y liste el archivo creado en el directorio /opt/rke/etcd-snapshots
ls -ltr /opt/rke/etcd-snapshots -
Salga del servidor student-X-master
exit[student@student-X-master ~]$ exit logout Connection to student-X-master closed. [student@student-X-aio rke-cluster-users]$ -
Asegurarse de estar ubicado en el directorio donde se encuentra el archivo cluster.yml para realizar la eliminación del cluster de RKE de usuarios/aplicaciones con el comando rke remove y simular un desastre del cluster. Cuando solicite confirmación responda a la pregunta con y
cd ~/rke-cluster-users/rke removeCuando el proceso de eliminación del cluster para simular un desastre termine, verá un mensaje similar al siguiente:[student@student-0-aio rke-cluster-users]$ rke remove INFO[0000] Running RKE version: v1.3.1 Are you sure you want to remove Kubernetes cluster [y/n]:INFO[0059] Removing local admin Kubeconfig: ./kube_config_cluster.yml INFO[0059] Local admin Kubeconfig removed successfully INFO[0059] Removing state file: ./cluster.rkestate INFO[0059] State file removed successfully INFO[0059] Cluster removed successfully -
Verifique que ya no cuenta con acceso al cluster con los siguientes comandos:
kubectl get nodesLos comandos de este paso deben de fallar, debido a que el cluster ya no existe.kubectl get pods -A -
Ahora podemos proceder a la restauración y recuperación del cluster que fue eliminado anteriormente, utilizando el siguiente comando:
Cuando el proceso de restauración finalice, verá un mensaje similar al msiguiente:rke etcd snapshot-restore --config ~/rke-cluster-users/cluster.yml --name snapshot-users.dbINFO[0097] Finished restoring snapshot [snapshot-users.db] on all etcd hosts -
Ejecute los siguientes comandos para verificar la recuperación del cluster:
kubectl get nodesLos comandos de este paso deben de funcionar correctamente. Con esto se concluye la primera parte del laboratoriokubectl get pods -A
Parte 2: Backups y Disaster Recovery de Rancher Server mediante un Snapshot de RKE
-
Ingresar al ambiente de laboratorio en el servidor student-#-aio al cluster de usuarios de Kubernetes, exportar la variable de ambiente KUBECONFIG
export KUBECONFIG=~/rke-cluster-aio/kube_config_cluster.yml -
Ahora e procede a tomar el Snapshot o Respaldo:
Cuando la toma del Snapshot termine, deberá visualizar un mensaje similar al siguiente:rke etcd snapshot-save --name snapshot-rke-rancher.db --config ~/rke-cluster-aio/cluster.ymlINFO[0005] Waiting for [etcd-snapshot-once] container to exit on host [student-0-aio] INFO[0005] Removing container [etcd-snapshot-once] on host [student-0-aio], try #1 INFO[0005] Finished saving/uploading snapshot [snapshot-rke-rancher.db] on all etcd hosts -
Ingrese al servidor student-X-aio, el cual tiene el rol de ETCD en el ambiente de laboratorio:
ssh student@student-X-aio -i ~/student-X-private_key.pem -
Verifique y liste el archivo creado en el directorio /opt/rke/etcd-snapshots
ls -ltr /opt/rke/etcd-snapshots -
Salga del servidor student-X-aio
exit[student@student-X-aio ~]$ exit logout Connection to student-X-aio closed. [student@student-X-aio rke-cluster-aio]$ -
Asegurarse de estar ubicado en el directorio donde se encuentra el archivo cluster.yml para realizar la eliminación del cluster de RKE de Rancher Server con el comando rke remove y simular un desastre del cluster. Cuando solicite confirmación responda a la pregunta con y
cd ~/rke-cluster-aio/rke removeCuando el proceso de eliminación del cluster para simular un desastre termine, verá un mensaje similar al siguiente:[student@student-0-aio rke-cluster-aio]$ rke remove INFO[0000] Running RKE version: v1.3.1 Are you sure you want to remove Kubernetes cluster [y/n]:INFO[0059] Removing local admin Kubeconfig: ./kube_config_cluster.yml INFO[0059] Local admin Kubeconfig removed successfully INFO[0059] Removing state file: ./cluster.rkestate INFO[0059] State file removed successfully INFO[0059] Cluster removed successfully -
Verifique que ya no cuenta con acceso al cluster con los siguientes comandos:
kubectl get nodesLos comandos de este paso deben de fallar, debido a que el cluster ya no existe.kubectl get pods -A -
Verifique el ingreso a Rancher Server por medio de la consola Web, no deberá estar disponible, ya que el cluster donde se ejecuta acaba de eliminarse.
-
Ahora podemos proceder a la restauración y recuperación del cluster que fue eliminado anteriormente, utilizando el siguiente comando:
Cuando el proceso de restauración finalice, verá un mensaje similar al msiguiente:rke etcd snapshot-restore --config ~/rke-cluster-aio/cluster.yml --name snapshot-rke-rancher.dbINFO[0097] Finished restoring snapshot [snapshot-rke-rancher.db] on all etcd hosts -
Realizar un reinicio a nivel del sistema operativo en donde se ejecuta el cluster RKE para Rancher Server
sudo reboot -
Ingresar al ambiente de laboratorio en el servidor student-#-aio al cluster de usuarios de Kubernetes, exportar la variable de ambiente KUBECONFIG
export KUBECONFIG=~/rke-cluster-aio/kube_config_cluster.yml -
Ejecute los siguientes comandos para verificar la recuperación del cluster:
kubectl get nodesLos comandos de este paso deben de funcionar correctamente. Nota: Puede tardar varios minutos en en regresar la consola de Rancher serverkubectl get pods -A -
Verifique el ingreso a Rancher Server por medio de la consola Web, deberá estar disponible y funcionando corerctamente, ya que acaba de ser restaurado. Con esto se concluye el laboratorio